
RTX2080/RTX2080Ti显卡全面评测 RTX20系电脑显卡怎么样?(2)
作为GPU显卡行业的领头羊,NVIDIA的新产品发布节奏多年来一直非常稳,探析一下这个革命性的Turing架构,以及全新的RTX 2080 Ti、RTX 2080两款高端型号到底表现如何。...
二、架构解析之全新内核体系
既然是一个全新设计的架构,我们就要好好看一看这个以计算机科学之父、人工智能之父艾伦·麦席森·图灵(Alan Mathison Turing)命名的Turing图灵新架构到底有哪些过人之处,不过硬件架构总是伴随各种高深晦涩的技术名词、技术原理,即便专业人士也得好好研究才行,所以这里我们仅从高级层面,介绍一下新架构的大致设计、技术概况,以及能带来的实际好处。
在以往,NVIDIA为专业级计算卡、消费级游戏卡设计的都是统一架构,只是具体内部模块布局、技术支持、核心大小不同。好处是可以统一开发,降低成本,坏处是缺乏针对性,技术资源要么浪费要么不够。
这一次,NVIDIA选择了分而治之。针对高性能计算、图形渲染、人工智能、深度学习等专业应用的是Volta伏特架构,目前只有一个超大核心GV100,是迄今为止GPU历史上最大的核心,台积电12nm工艺制造,集成多达210亿个晶体管,核心面积达815平方毫米,妥妥的怪物级核弹。

而针对游戏显卡的就是Turing图灵架构,也是台积电12nm(有说法称最初计划使用三星10nm),其中最大的核心TU102集成189亿个晶体管,核心面积754平方毫米,是仅次于GV100的史上第二大GPU核心。
相比上代Pascal帕斯卡家族的大核心GP102,它的晶体管数量增加了55%,面积则增大了60%,甚至是次级新核心TU104都超越了GF102,拥有136亿个晶体管、545平方毫米面积。

新架构核心之所以如此庞大,除了CUDA核心规模继续增大、升级Shading着色渲染之外,更关键的是RT Core光线追踪核心、Tensor Core人工智能核心的加入,这也是新架构革命性变化的根本支撑。
拥有全新着色性能的SM CUDA核心阵列、支持高达每秒100亿条光线计算的RT光线追踪核心、为实时游戏画面导入AI人工智能加速的Tensor核心,三者就构成了图灵架构的三大支柱,各自有不同分工又互相协作,共同实现新的游戏渲染画面。


同时,NVIDIA强调新架构的单个CUDA核心着色渲染性能是帕斯卡架构的1.5倍,第一次可以在4K分辨率、HDR开启的情况下,提供流畅的游戏体验,真正开启4K时代。
按照NVIDIA的说法,RTX 2080就能基本实现4K分辨率下60FPS的游戏帧率,RTX 2080 Ti更是能够达到70-80FPS。当然具体还要看游戏需求,以及游戏设置,特别是某些高要求的技术特性,光线追踪打开后别说4K了,就连1080p就比较吃力。
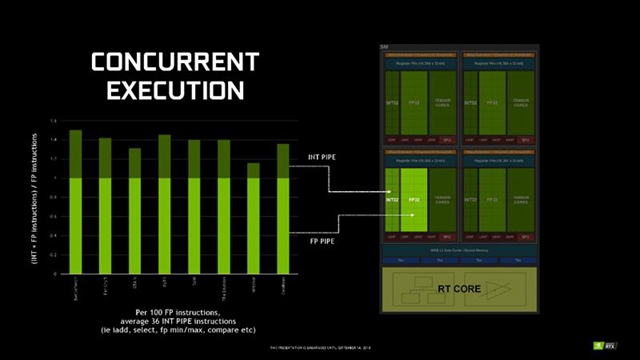
图灵架构的基本组成单元之一还是CUDA核心与SM流处理器阵列,这也是2006年的G80以来NVIDIA GPU的基石。
事实上,图灵架构的SM阵列也融合了伏特架构的不少特性,相比帕斯卡架构差别还是挺大的,比如每一组TPC里的SM阵列由一个增至两个,同时SM内部的组成方式也截然不同。
帕斯卡架构每个SM阵列集成128个FP32浮点单元,图灵架构则改成了2个FP64双精度浮点单元、64个FP32单精度浮点单元、64个INT32整数单元、8个Tensor核心、一个RT核心。支持浮点和整数并发操作,并有新的执行数据路径,类似伏特架构汇总的独立线程调度。
按照NVIDIA的统计,每执行100个浮点指令,平均会有36个整数指令,两种指令可以并发执行。
如此一来,帕斯卡架构的整数和浮点计算就可以分配得更加均衡,并与新的Tensor、RT核心相配合,更合理、高效地完成各种负载。
整体而言,图灵核心的CUDA阵列可以每秒执行14万亿次FP32浮点操作、14万亿次INT32整数操作。
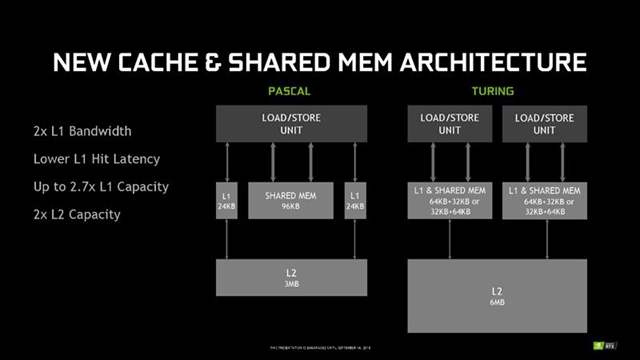
缓存架构也彻底变化,由两个载入/存储单元牵头,一级缓存和共享缓存整合在一起,而且容量灵活可变,可以是64KB+32KB,也可以是32KB+64KB,大大降低了延迟,带宽也翻了一番。
二级缓存容量则从3MB翻倍到6MB。
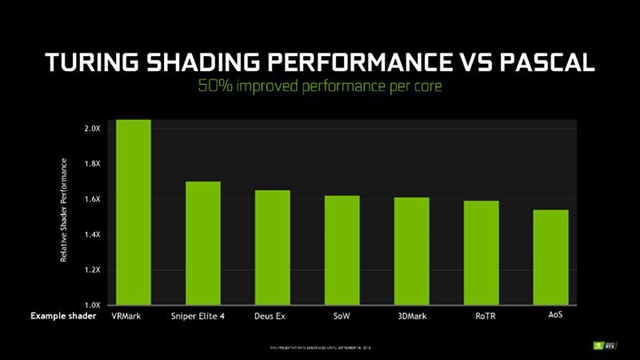
NVIDIA宣称,新架构每个CUDA核心的着色渲染性能比上代平均提升50%,部分游戏可达70%左右,VRMark虚拟现实测试成绩甚至翻了一番还多。
当然这只是基础理论上的数字,实际性能还要看其他部分和整体指标。

图灵架构还首发搭配新一代GDDR6显存,目前业界最快,等效频率高达14GHz,搭配352-bit位宽可以带来616GB/s的惊人带宽,相比于GTX 1080 Ti在位宽不变的情况下提升了27%,也比用了2048-bit HBM2高带宽显存的AMD RX Vega 64高了27%。
而且关键是,GDDR6的成本比HBM2低得多。
另外,NVIDIA还对新显存进行了各种优化,信号窜扰降低了40%,更利于运行稳定和进一步超频。

1.5万i7-8700K配RTX2080高性能电脑配置推荐 高性能全能型电脑
RTX20系显卡给为我们带来更好的性能与画质体验,搭载GDDR6全新显存,并加入了光线追踪技术。下面针对RTX2080显卡,推荐一套八代i7-8700K配RTX2080高性能DIY电脑配置推荐,硬件选用...

NVIDIA RTX2080显卡开箱图赏 图灵架构引入光线追踪技术
NVIDIA GeForce RTX 20系显卡正式发布的,该系列显卡最大亮点在于引入了光线追踪技术,为大家带来的是关于NVIDIA RTX2080显卡开箱图赏,一起来欣赏一下吧。...

GTX1080与RTX2080规格对比 GTX1080Ti显卡还值得买吗?
最近NVIDIA已经正式发布了全新的RTX 20系显卡,该系列显卡基于全新的Turing图灵架构,采用了光线追踪技术,可谓在性能方面相比上一代显卡提升了不少...

全品牌RTX2080/RTX2080Ti价格和参数对比 RTX2080(Ti)多少钱?
8月21日,Nvdia在德国正式发布了全新的RTX20系显卡,一共发布的新显卡产品有三款,分别是最高端的RTX2080Ti,还有相对更高端的RTX2080和RTX2070Ti,由于RTX2070显卡会在今年10月份才...

显卡天梯图秒懂RTX2080性能排行 RTX2080性能如何
近日NVIDIA正式发布了全新的RTX20系列显卡,此次带来的新显卡一共有三款。其中最先上市的是RTX2080,由于这款显卡将于9月才会正式上市,所以尚未解禁,具体的性能跑分数据带评测出...

GTX1080Ti与RTX2080Ti规格对比 RTX2080Ti和GTX1080Ti哪个好?
2018年8月20日24点,NVIDIA在德国科隆国际游戏展上举办了GeForce Gaming Event展前发布会,正式发布全新一代的GeForce 20系列游戏显卡,发布会带来了显卡一共有三款,分别是RTX207...
万元级i7-8700K配RTX2080高端游戏电脑配置推荐 全新20系显卡平台





NVIDIA RTX 2070显卡曝光 NVIDIA RTX2080显卡明晚发布
英伟达计划在8月21晚上推出全新的20系显卡,看起来这一次推出的是RTX 2080和RTX 2080 Ti显卡,支持实时光线追踪以及更加强大的性能,售价方面据传RTX 2080为800美元,而RTX 2080 Ti...